This topic includes the following subtopics:
- ISAM file structure
- ISAM file types
- Index caching
- Portable storage format
- Large sector drives
- ISAM input and output statements
- ISAM routines
We use RMS ISAM on OpenVMS for native compatibility. All other systems use Synergy ISAM. (See the OpenVMS Record Management Services Reference Manual for information on how to use RMS ISAM.)
A Synergy ISAM file is used for high-speed, keyed access and ordered sequential access. As your file grows, high-speed, keyed access is maintained. Your ISAM file’s size can grow to fit the need of your application, given the physical limitations of your disk. For example, we can have an ISAM file that contains a record for each of our customers. A record in an ISAM file consists of a set of fields. Each field stores a specific item of data, such as a customer number, a first and last name, a company name, a street address, a city, a ZIP Code, or a telephone number.
If we wanted to find a particular customer in a non-ISAM database file, such as customer number 125 or customer B. Jones, our program might have to search the entire file. Synergy ISAM, however, provides an access method that uses an index. An index enables you to quickly find specific records in a database file without having to search the entire file and without your program having to look at extra records. This is called keyed access. It also enables you to define an order for the sequential processing of a database file. This is called sequential access.
Each index in an ISAM file is defined by a key. A key is one or more fields or portions of fields from a record that are used to locate that record. Keys are defined when the ISAM file is created. For example, we can define a key for our customer number field that places customer numbers in ascending or descending order within the corresponding index.
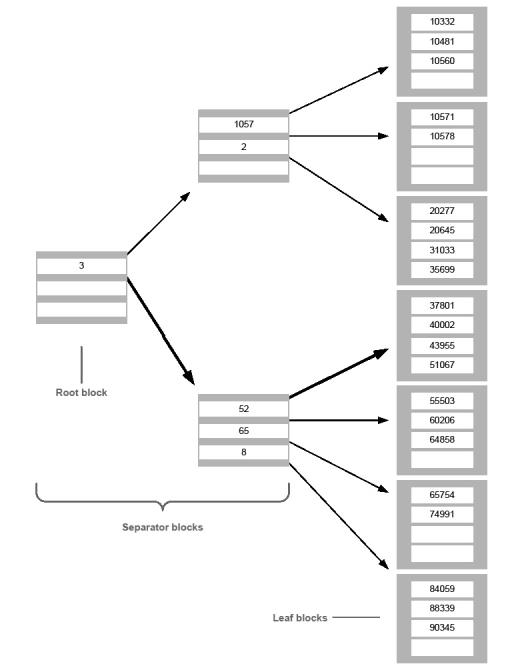
An ISAM file’s index contains leaf entries, which are sequentially ordered key values that point to corresponding data records. For example, the index defined by our customer number key, as illustrated in figure 1, contains the customer numbers (key values) in descending order for all customers in an ISAM file. These customer number entries point to data records. The data records are in no particular order. The index, however, is always in a specific order as defined by the key. In this case, the index is in descending order by customer number.
ISAM indexes are also structured hierarchically so that access to any particular record occurs with a minimum of index reading. Access to any data record by a particular key requires the same amount of index reads, provided the index doesn’t change. This number is determined by the index depth. Keyed access requires one index READ for each level of the index. The number of levels required for an index is universally proportional to key length. Large ISAM files (one million or more records) with long keys (45 or more characters) have five or more levels of index depth.
|
As shown in figure 1, an ISAM file’s index is composed of blocks. A block is the smallest unit of an index that can be read or written at one time, and block size is set when you create an ISAM file. (Note that to simplify the diagram, the block size in the diagram is artificially small.) The index in the diagram is three levels deep. In this case, separator blocks make up the first two levels of the index. (Any ISAM file with more than one index block has separator blocks.) The third or last level is made up of leaf blocks, which contain sorted key values (in this case, customer numbers) with a one-to-one correspondence between each leaf entry and the data record to which it points. The separator blocks exist as pathways to the leaf entries and are composed of pointers to lower-level index blocks and separator values that narrow the range of key values. The root block is a special separator block that is read first on any keyed access.
For example, let’s assume we want to access the data record for customer number 40002 by our customer number key using the following statement:
read(ch, rec, "40002")
First the root block is read. Synergy ISAM will determine that the number of our customer number (4) is greater than the value 3. We therefore read the separator block indicated by the first bold pointer in the diagram. Synergy ISAM will then determine that the first two numbers of our customer number (40) are less than the value 52 in the separator block. We therefore read the next block indicated by the second bold pointer in the diagram. Synergy ISAM will then find the entry 40002 within this block, which reads the data record for customer number 40002. By structuring the index hierarchically, Synergy ISAM enables us to access data records without having to read through the entire index. Also notice that reading any record by key value requires the same number of index reads.
An ISAM file can have more than one index. For example, we can define an index for the customer number field of our ISAM file and another index for the customer name field. These indexes enable us to quickly access the record for customer number 125, or the record for customer B. Jones.
The keys of an ISAM file also define the sequential order in which the file may be processed. For example, we can access our ISAM file sequentially by the customer number key, alphabetically by the customer name key, geographically by the customer city key, or by any other key that we define.
You can create an ISAM file using the ISAMC subroutine, the OPEN statement, or the bldism utility. See ISAMC, OPEN, or bldism for details.
The physical representation of a Synergy ISAM file reflects two files: one contains the data records and the other contains the indexes that point to the data. The index file has the default extension .ism (for example customer.ism). The data file has the extension .is1 (for example, customer.is1). The two files are always referenced together as one ISAM file with the extension .ism.
If you specify an ISAM filename with an extension other than .ism (for example, customer.dat), the last character of the data file’s extension is replaced with a 1 (for example, customer.da1). However, if the last character of the specified filename’s extension is already numeric (for example, cust.ab1), the last character of the data file’s root filename is replaced with an underscore (for example, cus_.ab1). In both cases, the index file (customer.dat or cust.ab1) and the data file (customer.da1 or cus_.ab1) are always referenced by the name of the index file (customer.dat or cust.ab1).
When creating an ISAM file, you can specify one of three file types:
- Fixed-length
- Variable-length
- Multiple fixed-length
If your ISAM file is used for only one data structure, you can use the fixed-length format. With this file type, all data in the ISAM data partition is stored in the same length record, regardless of the actual size of the data within the record.
If your ISAM file is used for a predefined group of different sized data structures, you can use the multiple fixed-length record format. The size of the stored record is determined by the data passed to the STORE statement. With this file type, you can’t change the record lengths, using the WRITE statement, after the data has been stored. Multiple fixed-length files can have up to 32 different record lengths. Using this file type enables you to reduce disk storage requirements and the number of open files. This file type is more efficient in disk space usage than variable-length records for cases where there are a limited number of different record sizes. Change tracking is not allowed with multiple fixed-length files.
If your ISAM file is used to store different types of records and it has no set pattern to the record size, or if the data length might change after the initial data is stored, you can use variable-length records. Like multiple fixed-length records, the initial size of the stored data is determined by the size of the data passed to the STORE statement. With variable-length records, however, you can change the size of the record using the WRITE statement.
The isload and fconvert ISAM utilities recognize one additional file type called a counted file. The isutl utility may also create a counted file in the form of an exception file, due to specific failures encountered during the recovery process. Counted files are not supported by the OPEN statement. Each record in a counted file starts with a two-byte length, which is the length of the record written as a portable integer, followed by the record itself, padded out to an even number of bytes if the length is odd. The final two bytes of the file are 0xFFFF, or integer -1.
The Synergy runtime performs three types of caching, depending on how the file was opened.
- Files opened with exclusive access (SHARE:Q_EXCL_RW) get full caching (read and write). ISAM I/O is cached and is not written to disk until a CLOSE or FLUSH statement is processed. Blocks remain in read cache until that time.
- Files opened with exclusive “allow readers” access (SHARE:Q_EXCL_RO) get a write-through form of caching. ISAM I/O is cached, but all output is written simultaneously to disk. No WRITE operations are cached, but all READ operations attempt to come from cache. Blocks remain in read cache until a CLOSE or FLUSH statement is processed.
- Files opened without exclusive access (SHARE:Q_NO_EXCL) get a write-through form of caching. ISAM I/O is cached, but all output is written simultaneously to disk. No WRITE operations are cached, but all READ operations attempt to come from cache. Blocks remain in read cache until the file is updated by another user or a CLOSE or FLUSH statement is processed.
In all cases, if the cache becomes full before a CLOSE or FLUSH is issued, the oldest blocks will be flushed.
Synergy ISAM storage format is the same on all Synergy DBL systems (except OpenVMS); therefore, you can copy ISAM files to any Windows or Unix system and access them without conversion. This portable storage format also enables you to access ISAM files across heterogeneous networks.
|
|
Using integer data in your records may affect portability. Integer data is not universally portable unless you define it using the I option in bldism or the ISAMC subroutine. If you use the I option, files can be moved to other machines and accessed across heterogeneous networks without having to apply any conversion at the application layer. |
Portable integer data can be stored in an ISAM file and retrieved portable across all platforms except OpenVMS.
Revision 6 ISAM files target the performance of Advanced Format large sector drives (sometimes referred to as 512e or 512n, and most SSDs) by reading and writing index blocks on 4K boundaries. The page size defaults to 4K, or 4096 bytes. (See Page size for more information.) If you want a smaller page size, you must explicitly specify it when the file is created.
|
|
You must use Revision 6 ISAM with large sector drives if you want them to operate efficiently. |
ISAM input and output statements
The following input and output (I/O) statements can be used with ISAM files:
The following system-supplied ISAM subroutines and functions enable you to manipulate ISAM files from within your applications:
