When a structure contains no field definitions, you can load definitions from an existing definition file (also referred to as an include file). An include file contains field definitions, optionally preceded by the RECORD, STRUCTURE, or COMMON statement. A single file can contain multiple record definitions.
|
|
If your include file uses .DEFINEs within field definitions, for example, custnm ,a NAMELEN you must substitute those definitions with the actual values. |
When an include file is processed, information is loaded into the field definitions in the following manner:
- The field name is set to the field identifier. For unnamed fields, the field name is set to NONAME_nnn, where nnn is a number starting with 001 and incrementing.
- The field’s short description is set to the comment on the field definition line. If there is no comment on that line, it is set to the field name.
- The field’s long description is set to all contiguous comment lines following the field definition, including the comment on the field definition line, if any.
- The data type is set to the data type. The Load Fields function does not support data types Enum and Struct. (Because the data type of Enum and Struct fields is the enumeration or structure name, Load Fields cannot tell them apart.) Fields of these types will generate an error.
- The data size is set to the length of the field.
- The precision information is set if the field type is implied-decimal.
- The dimension is set if the field is arrayed.
- The group flag is set if the field defines a group.
- Overlay information is set if the field is an overlay. Field position indicators (e.g., “name ,a25 @10”) are not supported.
- The exclusion flags for Language, Toolkit, and ReportWriter are not set for named fields, but are set for unnamed fields.
- The exclusion flag for Web is not set for either named or unnamed fields.
- Justification is set to left for alpha (a) fields and right for numeric (d or i) fields.
To load fields from a definition file,
| 1. | On the Structure Definitions list, highlight the structure that you are going to load the fields into. |
| 2. | Select Structure Functions > Edit Attributes. |
| 3. | Select Attributes > Fields. |
| 4. | From the Field Definitions list, select Field Functions > Load Fields. |
|
|
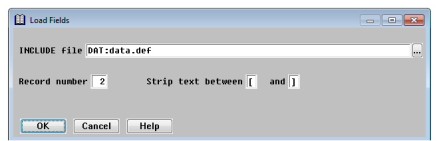
| 5. | Enter data in each field as instructed below. |
INCLUDE file
Enter the name of the include file from which to load the fields. You can include a full path or logical name. On Windows, you can click the drilldown button to browse for a file to select. If you don’t specify an extension, it defaults to .def.
Record number
If the .INCLUDE file contains more than one record, specify which record to use. For example, if your .INCLUDE file contains three records and you want to use the second one, enter 2. The default record number is 1.
Strip text between
Comments in the .INCLUDE file are loaded into the field’s short and long description fields as described above. You can strip irrelevant data, such as record offsets, by specifying the two characters between which all text should be stripped. The specified characters are stripped as well. Both characters must be non-blank.
For example, a line in your .INCLUDE file might look like this:
csname ,a30 ;[10,40]Customer name
To strip the information in brackets, enter “[” and “]” in the Strip text between fields, then the short description stored for the field will be “Customer name.”
| 6. | Exit the window to load the fields. |
If an error occurs while fields are being loaded, you’ll get an error message indicating which field caused the error. No additional fields are loaded. You must delete all fields that were successfully loaded before attempting to load from the .INCLUDE file again.
