XML (Extensible Markup Language) is a standard that specifies a syntax that enables you to create your own markup language. It wraps all data in tags that identify what each piece of data represents. As the name suggests, you can define an unlimited number of tags to define the data in the XML document. XML looks similar to HTML in that it employs the start-tag/end-tag mechanism to delimit the data.
The Synergy XML API gives you direct access to XML from within your Synergy programs. It enables you to
- parse an XML file or string into a memory-based XML document that represents a DOM tree. (See DOM trees for more information.) Parsing the file means to disassemble the XML so that your Synergy program can process it.
- iterate through the DOM tree to access the XML data. This entails finding the root element, being able to iterate recursively through its children, and being able to get text and attributes for all these elements.
- assemble Synergy data into a memory-based XML document. This includes being able to specify an element’s children, attributes, and text values.
- write the contents of a memory-based XML document to a file or XML string.
This topic includes the following:
- XML documents
- DOM trees
- XML API routines
- Parsing and processing XML data
- Assembling Synergy data in XML format
- Synergy XML API defines
XML documents
Each XML document, whether in memory or in a file or string, has one root element. All document content is defined by this root element and its children. An element is represented by a start tag and an end tag delimiting its text and/or children. Between the tags, each element may have zero or more attributes that further describe the element. In addition, each element may have zero or more child elements. These child elements also have their own attributes, text values, and/or children.
Here’s an example of XML describing the weather in Seattle:
<?xml version="1.0"?>
<weather-report>
<date>March 25, 1998</date>
<time>08:00</time>
<area>
<city>Seattle</city>
<state>WA</state>
<region>West Coast</region>
<country>USA</country>
</area>
<measurements>
<skies>partly cloudy</skies>
<temperature>46</temperature>
<wind>
<direction>SW</direction>
<windspeed>6</windspeed>
</wind>
<humidity>87</humidity>
<visibility>10</visibility>
</measurements>
</weather-report>
A well-formed XML document satisfies the following rules:
- It must have a single, unique root element.
- Every element must have a start tag and an end tag.
- Element and attribute names are case sensitive and cannot contain spaces.
- Elements must be properly nested; they cannot have structural overlaps.
- Certain characters must be escaped or represented by a combination of characters.
- Attribute values must be enclosed in quotation marks.
- Empty elements have a special form to which they must adhere.

Creating or processing large (multi-megabyte) XML documents requires an even larger amount of memory than the original document. If you think there is the potential to run out of memory, you must use an ONERROR($ERR_CATCH) to trap the “Not enough memory for desired operation” error ($ERR_NOMEM). If you want to simulate an out-of-memory condition, you can set the MAXMEMMAX environment variable to limit the amount of memory the runtime will use.
Embedding an XML document
You can embed an XML document within another XML document using the CDATA syntax. Because the text in a CDATA node is treated as plain text by the parser, instead of being processed as XML, CDATA is used to escape text that would otherwise be recognized as markup. For example, you might define an XML element as a CDATA node if your text contains a lot of “<” and “&” characters.
A CDATA node is formatted like this:
<node_name> <![CDATA[embedded XML here]]> </node_name>
To access the CDATA data node from the XML document, execute %XML_ELEM_GETTEXT on the parent node that contains CDATA.
|
|
The XML API does not support embedding CDATA within the text stream. For example, <mynode>my text<![CDATA[more text]]>more text</mynode> is not supported. |
DOM trees
An XML parser is used to load an XML document into the memory of your computer. Parsing the document produces a tree view of the document that can be traversed to retrieve and manipulate the XML data. This tree view of the XML document is called a DOM (Document Object Model) tree. The document’s root element is the top level of the tree. This element can have one or many child elements, or nodes, that represent the branches of the tree. Using a DOM, you can create a document, navigate its structure, and add, modify, or delete its elements.
Figure 1 shows what the following XML document would look like as a DOM tree:
<?xml version="1.0"?> <structure name="mystruct" size="284" > <field name="id" type="decimal" size="4" /> <field name="description" type="alpha" size="250" /> <field name="username" type="alpha" size="30" /> </structure>
|
|
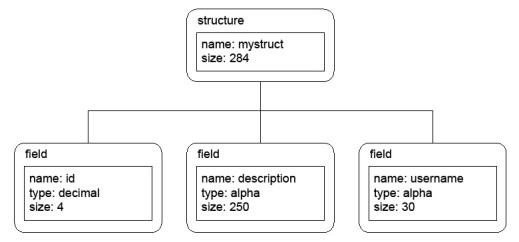
In this example the topmost tag, structure, becomes the root element. This structure element has two attributes: name and size. Below it are the three child elements representing the three field tags. Each of these children in turn has three attributes: name, type, and size. The “<?xml version=“1.0”?>” declaration is ignored in our examples.
XML API routines
Each Synergy XML API routine can be called as either a subroutine or a function; however, if you call it as a subroutine you will not be able to access its return value. To use the XML API, you must do the following:
On Windows and Unix,
- Include the DBLDIR:synxml.def file in your Synergy program.
- Link the DBLDIR:synxml.elb library into your Synergy program.
On OpenVMS,
- Link your program as follows:
link program,sys$share:synrtl/opt,sys$input:/opt
SYNXML/share
^Z
Alternatively, you can copy synrtl.opt to a local directory and add SYNXML/SHARE to your options file.
In Synergy .NET,
- To use the XML API for .NET Framework development, add a reference to Synergex.SynergyDE.synxml.dll. For .NET or .NET Standard development, use the Synergex.SynergyDE.synxml NuGet package.
All programs that use the XML API must be built using the -T or /TRIM compiler option (which trims trailing null arguments from XCALLs and function references), and the -X or /IMPLICIT compiler option (which automatically declares all undefined function references as external ^VAL functions).
XML parser routines
Before you can parse and manipulate an XML document, you need an XML parser. The %XML_PARSER_xxx routines create a parser and parse an XML file or string into memory as a DOM tree. They include
Here’s how you would typically use them:
| 1. | Call %XML_PARSER_CREATE to create the parser. |
| 2. | Call either %XML_PARSER_PARSEFILE or %XML_PARSER_PARSESTRING, depending on whether the XML arrives as a physical file or an in-memory handle in a Synergy program. Both of these functions return an XML document that can be processed using the XML document routines (%XML_DOC_xxx). |
| 3. | Use %XML_DOC_DELETE to delete the document returned by %XML_PARSER_PARSEFILE or %XML_PARSER_PARSESTRING. |
| 4. | Call %XML_PARSER_DELETE to release the parser. |
XML document routines
The %XML_DOC_xxx routines enable you to manipulate the in-memory DOM tree representation of an XML document. They include
Here’s how you would typically use them:
Once an XML document has been parsed using the %XML_PARSER_xxx routines
| 1. | Get the document’s root element using %XML_DOC_GETROOT. |
| 2. | Process the root element using the XML element routines (%XML_ELEM_xxx). |
| 3. | (Optional) Depending on the needs of your Synergy application, write the XML document to an XML file using %XML_DOC_TOFILE or to an XML string using %XML_DOC_TOSTRING. |
If you are assembling Synergy data in XML format
| 1. | Create an XML document with %XML_DOC_CREATE. |
| 2. | Designate the root element with %XML_DOC_SETROOT. |
| 3. | Process the root element (and subelements) using the XML element routines (%XML_ELEM_xxx). |
| 4. | Depending on the needs of your Synergy application, write the XML document to an XML file using %XML_DOC_TOFILE or to an XML string using %XML_DOC_TOSTRING. |
| 5. | Release the XML document using %XML_DOC_DELETE. |
XML element routines
The %XML_ELEM_xxx routines enable you to manipulate an XML element. They include
You can get the following information from an element:
- An attribute value, using %XML_ELEM_GETATTRIBUTE
- A text value, using %XML_ELEM_GETTEXT
- The element’s children, using either %XML_ELEM_CHILDREN or %XML_ELEM_GETELEMENTSBYNAME
You can also set an attribute value with %XML_ELEM_SETATTRIBUTE, or set its text value with %XML_ELEM_SETTEXT.
XML attribute list routines
An attribute list is simply a list of attributes for a given element.
The %XML_ATTRLIST_xxx routines enable you to manipulate XML attribute lists. They include
Usually when you retrieve information about an attribute, you can use %XML_ELEM_GETATTRIBUTE and avoid calling these functions directly. Indirectly, %XML_ELEM_GETATTRIBUTE calls %XML_ATTRLIST_FIND to find the attribute by name and then calls %XML_ATTR_GETVALUE to get the attribute’s value. However, you may also choose to iterate through an element’s attributes (for example, if you don’t know the names of the attributes):
| 1. | To get all of the attributes for an element, call %XML_ELEM_ATTRIBUTES, which returns an attribute list instance. |
| 2. | Call %XML_ATTRLIST_COUNT to get the number of attributes in the list. |
| 3. | Use a Synergy FOR loop to get each attribute in the list using %XML_ATTRLIST_ITEM. |
XML attribute routines
The %XML_ATTR_xxx routines enable you to manipulate a single XML attribute. They include
Use these routines to get or set the attribute’s name or value. (In most cases, however, you can simply use %XML_ELEM_SETATTRIBUTE to add or update element attributes.)
XML element list routines
The %XML_ELEMLIST_xxx routines enable you to manipulate a list of XML elements. They include
| 1. | Call either %XML_ELEM_CHILDREN or %XML_ELEM_GETELEMENTSBYNAME to obtain a list of elements. |
| 2. | Call %XML_ELEMLIST_COUNT to get the number of elements in the list. |
| 3. | Use a Synergy FOR loop to iterate through the list, getting each element by calling %XML_ELEMLIST_ITEM. |
You can also iterate through a list of elements looking for an element by name by calling %XML_ELEMLIST_FIND, or by tag by calling %XML_ELEMLIST_FINDTAG.
XML string routines
The %XML_STRING_xxx routines enable you to manipulate a dynamic string. This string enables the XML API to handle strings of any size, even those greater than the 65,535 limitation. You can append a regular Synergy alpha string using %XML_STRING_APPEND, append another dynamic string using %XML_STRING_APPENDDYN, or append a handle to the XML string using %XML_STRING_APPENDHANDLE.
When processing XML data in a Synergy program, you will typically need to change the XML string into a Synergy memory handle. The %XML_STRING_GETHANDLE routine provides the handle, and the %XML_STRING_GETSIZE routine provides its size.
If XML data arrives in a Synergy program as in-memory data, such as an alpha string or a D_HANDLE handle returned from the HTTP document transport API, in order to parse that data you must first create an XML string using %XML_STRING_CREATE and then call the appropriate append routine to add that data to the XML string. Then the XML string can be passed into %XML_PARSER_PARSESTRING. Likewise, going the other direction, if you have an XML document, you can call %XML_DOC_TOSTRING to first get an XML string and then call %XML_STRING_GETHANDLE to pass it into the HTTP API routines.
The XML string routines include
XML option routine
The %XML_OPTION routine sets a value for an XML option.
Parsing and processing XML data
This section describes the basic steps you need to take to parse (or disassemble) an existing XML document sent to your Synergy application and process the data so your application can use it. The document can be in the form of a Synergy alpha string or a file.
| 1. | Create a Synergy XML parser by calling %XML_PARSER_CREATE. |
| 2. | Parse the XML document by calling %XML_PARSER_PARSEFILE. |
| 3. | Get the root element by calling %XML_DOC_GETROOT. |
| 4. | Iterate through the DOM tree, beginning with the root element from the document created in step 3. You can iterate through the tree in many different paths using %XML_ELEM_CHILDREN, %XML_ELEM_GETELEMENTSBYNAME, and the %XML_ELEMLIST_xxx routines. |
| 5. | Retrieve XML data by getting the element’s attributes, associated text, and child attributes using %XML_ELEM_GETATTRIBUTE, %XML_ELEM_GETTEXT, and %XML_ELEM_CHILDREN, respectively. |
| 6. | Repeat step 4 and step 5 as needed for all elements in the XML document. |
| 7. | Use the XML data as desired in your application. |
| 8. | After parsing is done, release the parser by calling %XML_PARSER_DELETE. (You can perform this step any time after step 2, when parsing is complete.) |
| 9. | After the document is no longer needed, release it by calling %XML_DOC_DELETE. |
The following example (for Windows or Unix) uses the Synergy XML API to parse an XML file. For another example, see XML_to_Synergy_DBMS, available from Synergy CodeExchange in the Synergex Resource Center.
.include "DBLDIR:synxml.def"
main
.align
record
i ,i4
parser ,XML_PARSER_TYPE
doc ,XML_DOC_TYPE
root ,XML_ELEM_TYPE
elem ,XML_ELEM_TYPE
children ,XML_ELEMLIST_TYPE
tagName ,a250
attrValue ,a250
msg ,a250
proc
; Create parser instance
parser = %xml_parser_create()
; Parse the xml file
doc = %xml_parser_parseFile(parser,"hey.xml")
if .not.(doc)
begin
xcall xml_parser_error(parser,msg)
xcall test_writeit("error:"+%atrim(msg))
goto done
end
; Get the root element
root = %xml_doc_getRoot(doc)
if .not.(root)
begin
xcall test_writeit("error:empty root")
goto done
end
; Print out the tag name and the attribute name value
xcall xml_elem_getName(root,tagName)
xcall xml_elem_getAttribute(root,"name",attrValue)
xcall test_writeit("root:"+%atrim(tagName)+":"+%atrim(attrValue))
; Get the children of the root
children = %xml_elem_children(root)
; Iterate through the list of children
for i from 1 thru %xml_elemlist_count(children)
begin
elem = %xml_elemlist_item(children,i)
if .not.(elem)
begin
xcall test_writeit("error:empty element for index "+%string(i))
goto done
end
; Print out the tag name and the attribute name value
xcall xml_elem_getName(elem,tagName);
xcall xml_elem_getAttribute(elem,"name",attrValue)
xcall test_writeit(" child:"+%atrim(tagName)+":"+%atrim(attrValue))
end
done, if (parser)
xcall xml_parser_delete(parser) ;Delete the parser instance
if (doc)
xcall xml_doc_delete(doc) ;Delete the XML document
sleep(3)
endmain
; write a message to standard out
subroutine test_writeit
msg ,a
proc
open(1, o, 'tt:')
writes(1,%atrim(msg))
close 1
xreturn
endsubroutine
Given the XML file in Sample XML document, the output of this program is as follows:
root:structure:mystruct child:field:id child:field:description child:field:username
Assembling Synergy data in XML format
This section contains the basic steps required to create a well-formed XML document using Synergy program data for use by an external system. The document may be represented as a Synergy memory handle or as a physical file on the hard disk.
| 1. | Create the XML document by calling %XML_DOC_CREATE. |
| 2. | Create the root element of the XML document by calling %XML_ELEM_CREATE. |
| 3. | Specify that the element created in step 2 is the root element of the XML document by calling %XML_DOC_SETROOT. |
| 4. | Name the element using %XML_ELEM_SETNAME, and assign any necessary attributes using %XML_ELEM_SETATTRIBUTE. |
| 5. | Do the following for each subelement: |
- Create each subelement using %XML_ELEM_CREATE.
- Specify the subelement’s name and attributes by calling %XML_ELEM_SETNAME and %XML_ELEM_SETATTRIBUTE, respectively.
- Add each subelement to the parent element by calling %XML_ELEM_ADDCHILD.
| 6. | Write the XML document into an XML file by calling %XML_DOC_TOFILE. |
| 7. | If you need to write the XML document to a Synergy memory handle, create an XML string by calling %XML_DOC_TOSTRING. Get the handle and size of the XML string using %XML_STRING_GETHANDLE and %XML_STRING_GETSIZE, respectively. |
| 8. | Release the XML document by calling %XML_DOC_DELETE. |
The example below (for Windows or Unix) shows how to build the DOM tree for the structure example in Sample XML document. It writes the XML to a file called hey.xml. For another example, see XML_to_Synergy_DBMS, available from Synergy CodeExchange in the Synergex Resource Center.
.include "DBLDIR:synxml.def"
main
.align
record
doc ,XML_DOC_TYPE
root ,XML_ELEM_TYPE
f1 ,XML_ELEM_TYPE
f2 ,XML_ELEM_TYPE
f3 ,XML_ELEM_TYPE
proc
doc = %xml_doc_create
if (doc)
begin
root = %xml_elem_create
xcall xml_doc_setRoot(doc,root)
xcall xml_elem_setName(root,"structure")
xcall xml_elem_setAttribute(root,"name","mystruct")
xcall xml_elem_setAttribute(root,"size","284")
f1 = %xml_elem_create
xcall xml_elem_setName(f1,"field")
xcall xml_elem_setAttribute(f1,"name","id")
xcall xml_elem_setAttribute(f1,"type","decimal")
xcall xml_elem_setAttribute(f1,"size","4")
xcall xml_elem_addChild(root,f1)
f2 = %xml_elem_create
xcall xml_elem_setName(f2,"field")
xcall xml_elem_setAttribute(f2,"name","description")
xcall xml_elem_setAttribute(f2,"type","alpha")
xcall xml_elem_setAttribute(f2,"size","250")
xcall xml_elem_addChild(root,f2)
f3 = %xml_elem_create
xcall xml_elem_setName(f3,"field")
xcall xml_elem_setAttribute(f3,"name","username")
xcall xml_elem_setAttribute(f3,"type","alpha")
xcall xml_elem_setAttribute(f3,"size","30")
xcall xml_elem_addChild(root,f3)
xcall xml_doc_toFile(doc,"hey.xml")
xcall xml_doc_delete(doc)
end
endmain
Synergy XML API defines
The XML API uses the following type defines:
|
XML instance |
Type define |
|---|---|
|
Attribute |
XML_ATTR_TYPE |
|
Attribute list |
XML_ATTRLIST_TYPE |
|
Document |
XML_DOC_TYPE |
|
Element |
XML_ELEM_TYPE |
|
Element list |
XML_ELEMLIST_TYPE |
|
Parser |
XML_PARSER_TYPE |
|
String |
XML_STRING_TYPE |
For instance, you would pass XML_ELEM_TYPE handles to XML_ELEM_xxx routines and XML_ATTR_TYPE handles to XML_ATTR_xxx routines. You would not pass an XML_ATTR_TYPE handle to XML_ELEM_GETNAME, for example. If the wrong type is passed, an “Invalid external function data type” error ($ERR_INVEXFTYP) is generated.
The XML API also has a status define, XML_SUCCESS, that indicates an operation was successful. Many XML API functions return XML_SUCCESS on successful completion; they do not return this value if the operation wasn’t successful. We suggest you check your code as follows:
status = %xml_attr_setValue(attrid,"myname") if (XML_SUCCESS .eq. status) then ; Operation was successful else ; Operation was unsuccessful -- do error handling
Likewise, failure can be tested by
status .ne. XML_SUCCESS
